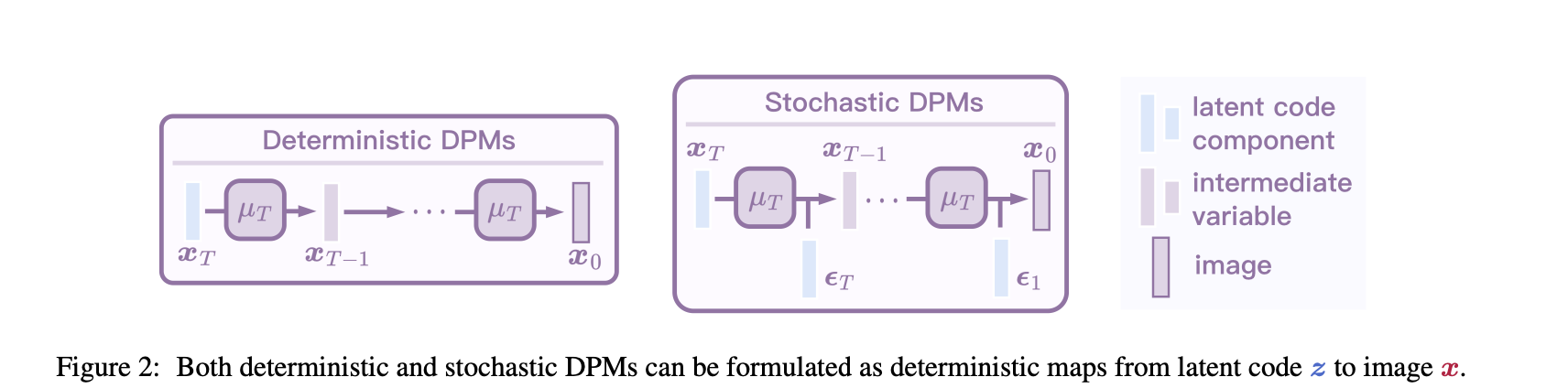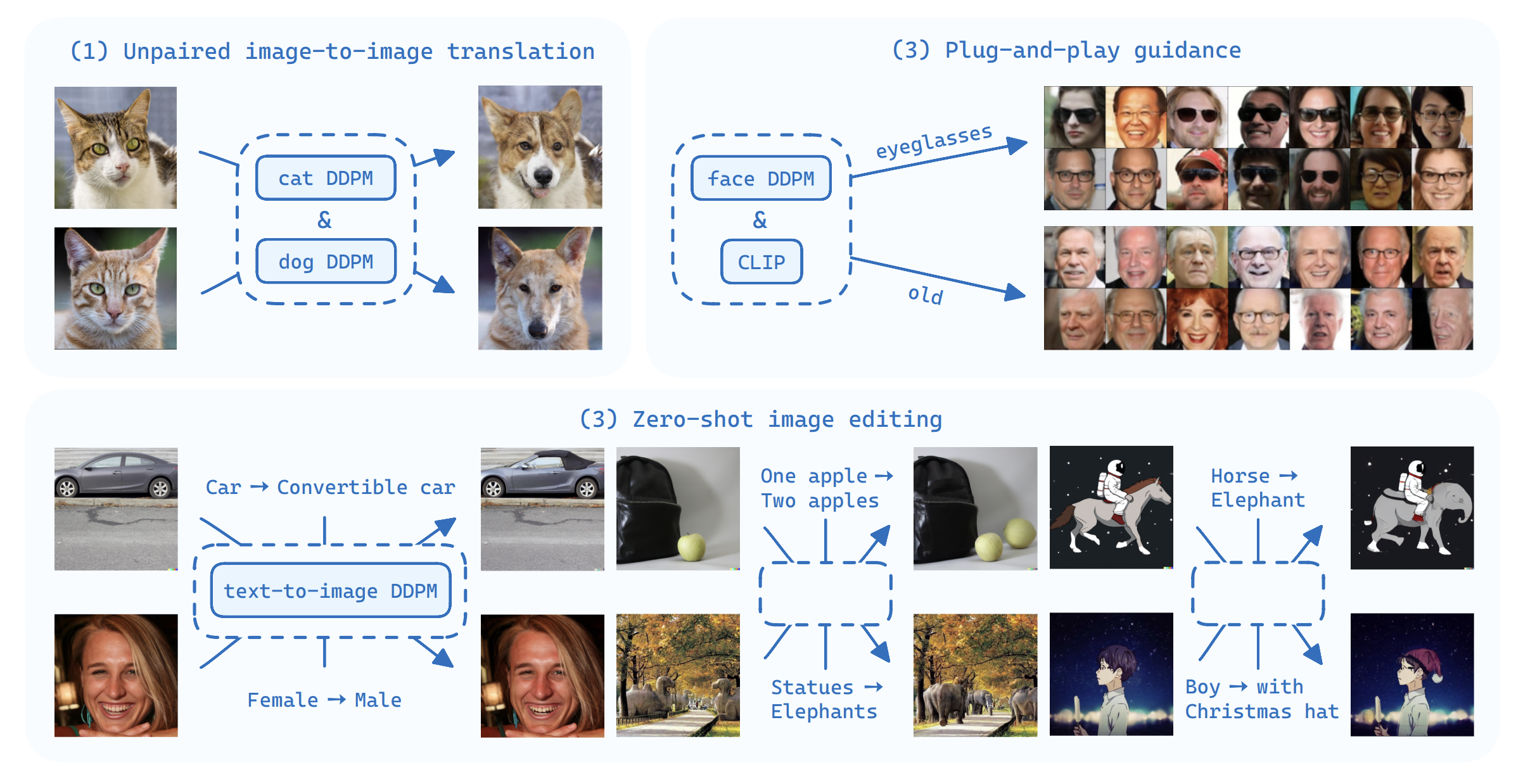
We define a new latent space for stochastic diffusion probabilistic models. This latent space allows us to perform: (1) Unpaired image-to-image translation with two diffusion models pre-trained independently (e.g., cat and dog). In this case, we can transfer the texture characteristics from an image of a cat to the model of a dog in an unsupervised fashion. (2) zero-shot image editing with a pre-trained text-to-image diffusion model. In this case, we can edit images with text prompts. (3) Plug-and-play guidance of a pre-trained diffusion model with off-the-shelf image understanding models such as CLIP. In this case, we are able to sub-sample a generative model of faces guided by attributes like "eyeglasses" or "old".